Clip Catalog
We censor our kids' faces on social media. Every video that goes out, every piece of content - their faces are blurred or covered. Non-negotiable.
So every time an editor reuses a piece of B-roll they have to censor the faces again. From scratch. Manually. Even if it's a clip we've used fifteen times before and censored fifteen times before because the source file is uncensored & nobody knows which version was the censored one or where it lives or if it even still exists. Every edit starts with this re-censoring process that just... shouldn't exist.
And then finding anything.
We have somewhere between 500 and 1000 clips of B-roll across Baby Acrobatics. Babies climbing things, hanging from bars, crawling on grass, eating food, doing things that make other parents nervous. All shot over months across different cameras & different locations. And the way you find a specific clip is you go "I remember there was this clip of him eating meat in a red shirt" and then you open a folder with 400 files named IMG_4523.MOV through IMG_5891.MOV and good luck.
You don't know the filename. You don't know which folder it ended up in. You just remember what was happening - what he was wearing, what he was doing, where it was shot. And there's no way to search for any of that because file systems don't know what's inside a video file.
Finding a single clip could take 20 minutes of scrubbing through footage. Multiply that by every clip needed for every edit and the search process was eating more time than the actual editing. The biggest bottleneck in the whole production workflow wasn't shooting or editing - it was just finding the right B-roll.
And then there was the chaos problem.
B-roll would end up in random folders. Different editors would pull clips onto different drives. Someone would reorganize things and now the paths are broken. Another editor tries to pick up a project and half the media is offline because the clips moved. You spend twenty minutes relinking everything & praying the file names match. Just a mess - every handoff between editors was a disaster waiting to happen.
So I built a catalog.
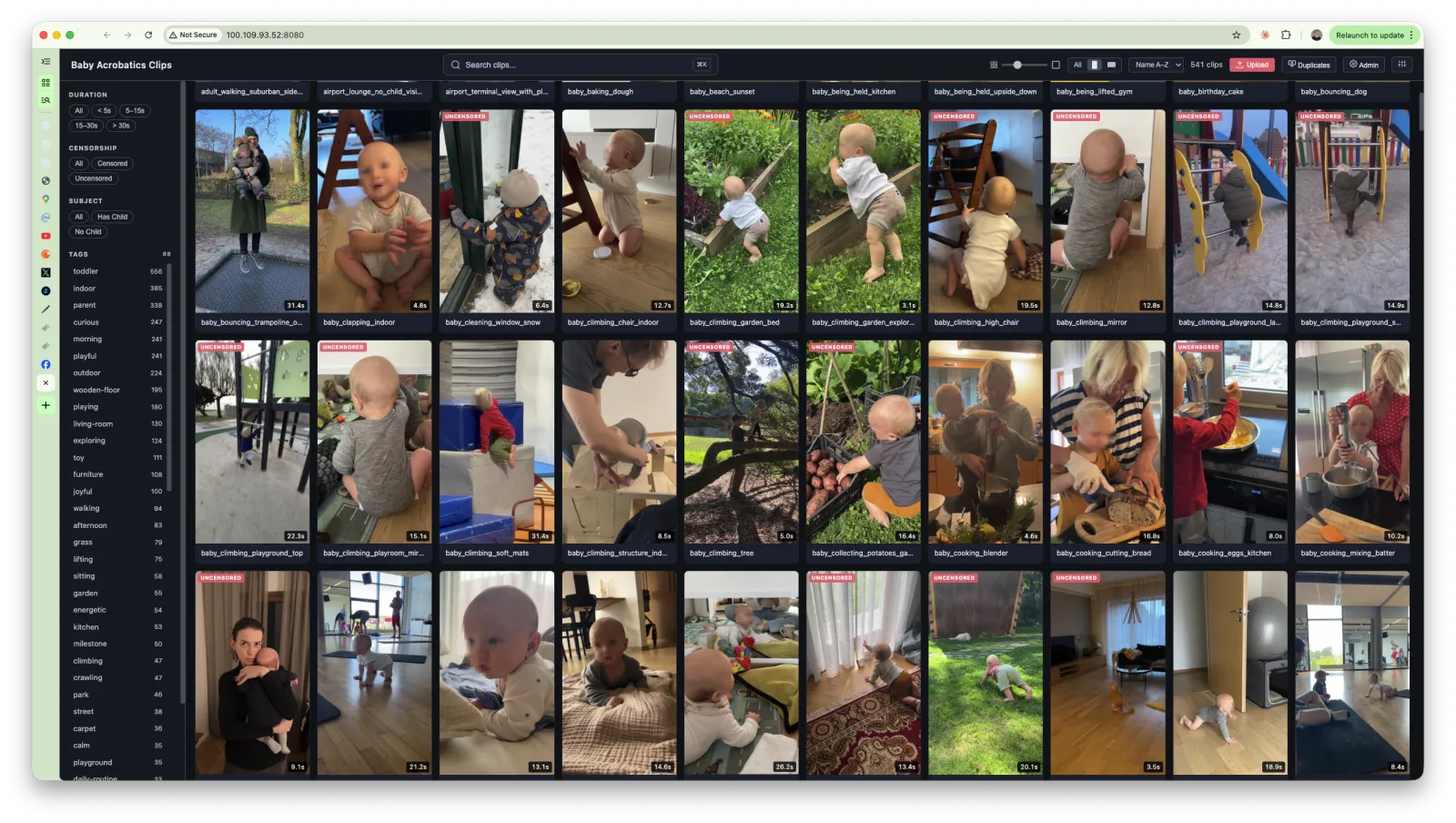
how it works
You drop videos into the inbox. The system picks them up and runs them through a pipeline:
- Frame extraction - pulls frames at 1fps and generates a filmstrip collage (a grid of every frame with timestamps, left to right, top to bottom)
- Vision analysis - sends the filmstrip to GPT-4o which looks at the frames and generates a deep structured JSON for every clip: what's happening, who's in it, what they're wearing & holding, what objects are visible, the environment, camera angle, mood, and an action summary describing the arc of what happens start to finish
- Tagging - the AI generates 8-15 specific searchable tags per clip (not generic stuff like "baby" or "outdoor" but things like "pikler-triangle", "red-shirt", "eating-meat", "supported-standing", "grass-surface", "golden-hour-lighting")
- Embedding - takes all that structured analysis and generates a vector embedding so the clip becomes semantically searchable
- Renaming - renames the file based on what the AI saw so instead of
IMG_4523.MOVyou gettoddler_climbing_pikler_triangle_park.MOV
After that the clip is fully indexed - every frame analyzed, everything described and tagged, the whole thing sitting in vector space ready to be found.
the search
The search is hybrid - full-text search (exact and prefix matching across descriptions, filenames, tags, action summaries) combined with semantic vector search (cosine similarity across embeddings).
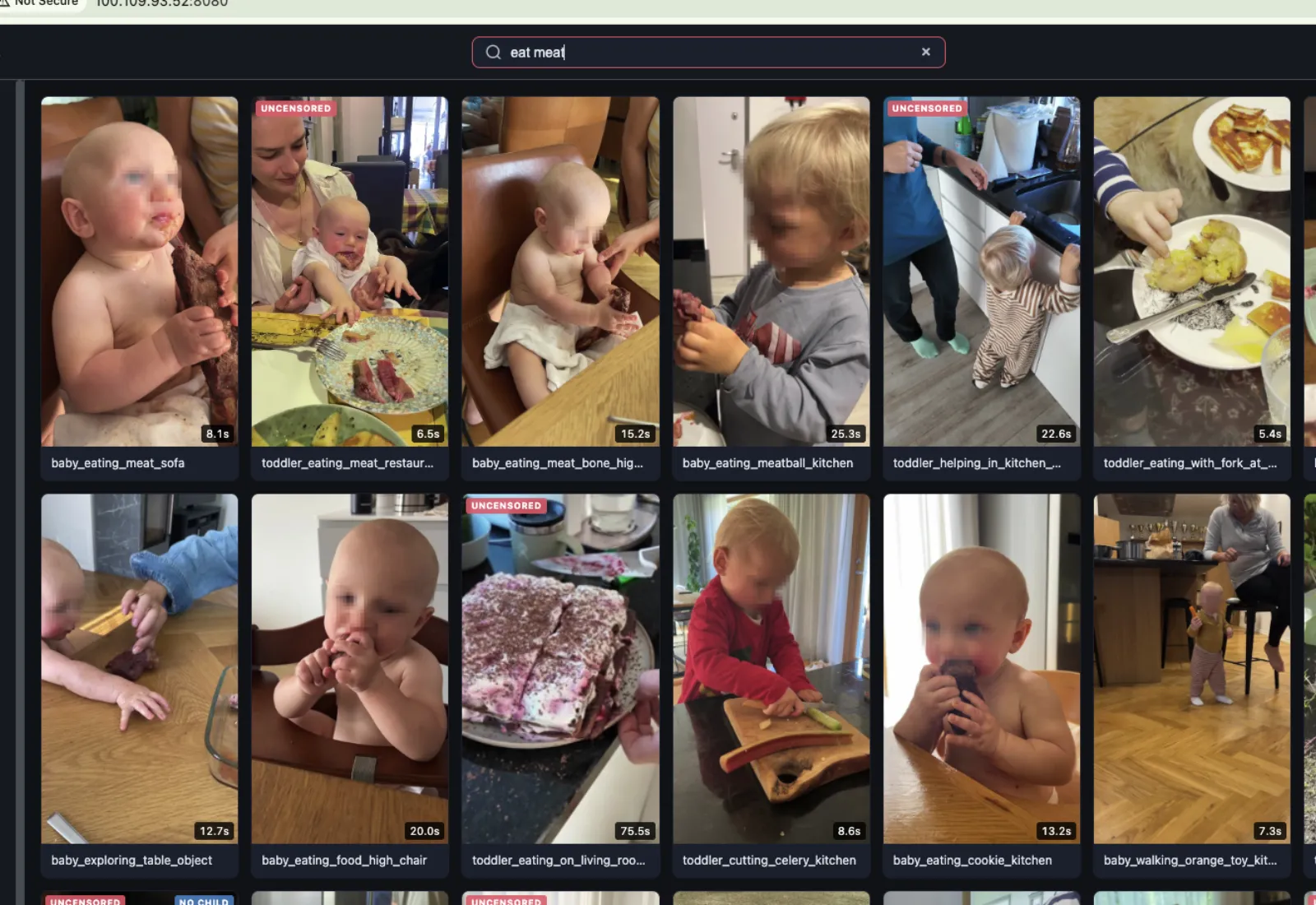
So you can search "eating meat red shirt" and it'll find:
- clips explicitly tagged with "eating" or "red-shirt" (exact match)
- clips where the AI described something like "toddler in a red cotton t-shirt biting into a piece of steak held in both hands" (semantic match)
The semantic part is what's actually useful because you often don't know the exact words the AI used to describe something. You just know what you're looking for - the way you'd describe it to another person - and the embeddings handle the translation. "The clip where he's hanging from the bar at the playground" finds it even if the AI described it as "child gripping overhead wooden dowel with both hands, feet dangling above rubber surface."
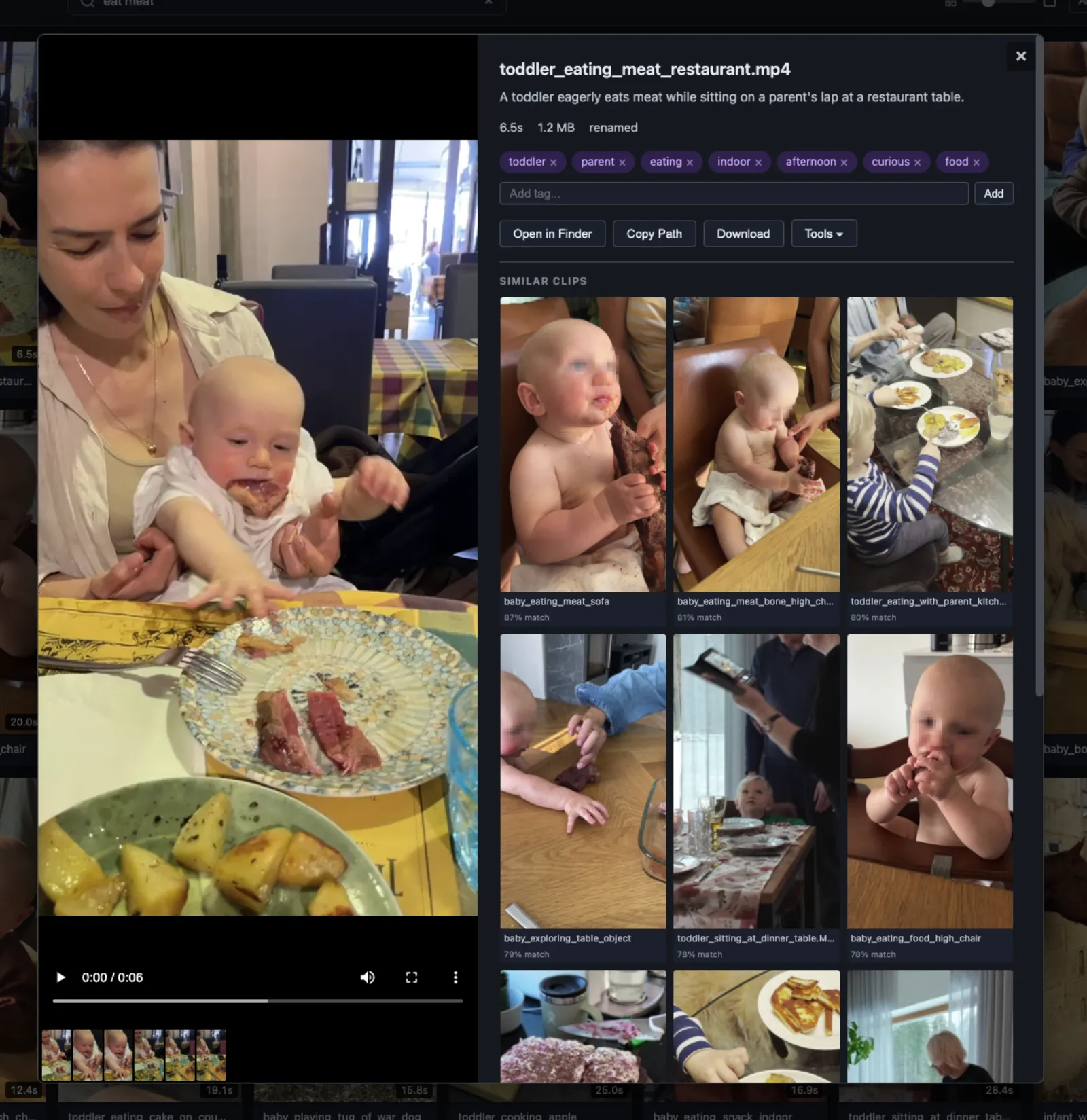
It also does similar clips - when you're looking at a clip it shows you other clips that are conceptually close in embedding space. So if you find one good shot of a baby crawling you instantly see all the other crawling clips ranked by similarity. I think this is the feature I use the most because editing is often "I need five different angles of roughly the same thing" & this just gives you that.
the editor workflow
The whole thing is hosted on our Tailscale network - not public, just accessible to our team. An editor working in Premiere or DaVinci opens the catalog in their browser, searches for what they need, finds the clip, clicks "Open in Finder." It opens right there in Finder. They drag it into their timeline. Done.
This is important because the source paths are always the same. The catalog doesn't move files around or create copies - it indexes the footage where it lives. So when an editor drops a clip into their timeline the path points to the canonical location on the shared drive & when another editor opens that same project later the media is right there. No relinking, no "media offline."
Before this every editor had their own mental map of where things were and if someone else had to pick up a project they were basically starting from zero. Now there's one source of truth & everyone's pulling from it.
censorship
Because every clip goes through vision analysis the system knows what's in every frame. So you can pre-censor the entire library once - run through everything, flag the clips that need face blurring, apply it to the source files in the catalog - and from that point forward every editor is pulling already-censored footage. The catalog is the single source & if it's censored there it's censored everywhere.
deduplication
When you've been shooting for years across multiple cameras & multiple editors have been pulling footage onto different drives you end up with duplicates everywhere. The system fingerprints every clip and detects duplicates automatically - so you can clean up the mess instead of storing five copies of the same clip in five different folders.
cost
GPT-4o-mini for the vision analysis and text-embedding-3-small for the embeddings. Analyzing the full catalog - hundreds of clips - costs less than a dollar. I thought the vision API would be expensive but at these volumes it's basically free.
what it changed
Before: "do we have a clip of X?" was a 20-minute dig through folders that usually ended with "I think we used to but I can't find it." Editors re-censored faces on clips they'd already censored. Projects broke when they changed hands because nobody could find the media.
Now you type what you remember into a search bar and the clip shows up. Click "Open in Finder" and drag it into your timeline. Paths are stable so projects don't break. Faces are already censored. Similar clips shows you five other angles of the same thing you didn't even know you had.
I wish I had this when I was doing content work for other brands - going through thousands of clips across multiple projects & editors, this would've saved so much time. I think it's a perfect tool for any content brand or production team that has a large B-roll library and needs to actually find things in it.
It's not revolutionary technology. It's literally just "extract frames, ask an AI what it sees, store the answer, make it searchable." But the difference in practice is kind of huge because the bottleneck in video production was never shooting or editing - it was finding the right footage & dealing with the chaos around it. And now that's basically gone.